
Quo Vadis, homo sapiens? Generatywna Sztuczna Inteligencja – przegląd problemów i zagrożeń

Tematem styczniowego webinarium realizowanego w roku akademickim 2023/24 w ramach cyklu „Rozmowy przy drugiej kawie" była sztuczna inteligencja. Jest to temat budzący wiele emocji. Wraz z wprowadzeniem przed rokiem ChataGPT praktycznie każdy mówi o sztucznej inteligencji. Mówi się o niej również w Szkole Głównej Handlowej w Warszawie,
W SGH powstało Międzykolegialne Centrum Sztucznej Inteligencji i Platform Cyfrowych – AI Lab, kierowane przez profesora Bogumiła Kamińskiego. W maju odbędzie się konferencja naukowa AI Spring. Sztuczna inteligencja w naukach ekonomicznych.
Prezentację w ramach webinarium przedstawił profesor Jerzy Surma reprezentujący Instytut Informatyki i Gospodarki Cyfrowej SGH. Profesor Surma jest niekwestionowanym autorytetem w sprawach cyfrowych – kieruje studiami podyplomowymi z Business Intelligence oraz Zarządzaniem cyberbezpieczeństwem, prowadzi też kanał na YouTubie poświęcony „rozumnemu życiu w cyberprzestrzeni”: www.youtube.com/@JerzyAndrzejSurma
Prezentacja skoncentrowała się na następujących wątkach:
- schematy działania dużych modeli językowych (ang.: LLM – Large Learning Models),
- jakość sztucznej inteligencji – jakie ma poważne ograniczenia i tym samym jakie ryzyka generuje?
- silne strony sztucznej inteligencji, które w dłuższym okresie też mogą prowadzić do ryzyk.
Jak widać z powyższego, tematy raczej koncentrowały się na ciemnych stronach sztucznej inteligencji. Duże modele językowe (LLM) są budowane w oparciu o tzw. duże korpusy językowe, czyli zbiory tekstów. Tym samym jakość tych zbiorów tekstów silnie determinuje jakość generowanych odpowiedzi.
Przykładowo dla ChatGPT 3 były brane pod uwagę następujące korpusy językowe:
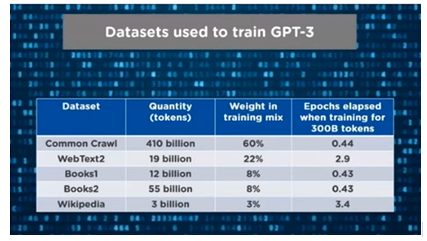
Głównym korpusem językowym dla ChatGPT 3,0 jest Common Crawl. Co to jest? Są to teksty generowane z publicznie dostępnych źródeł danych w internecie. Istotne jest to, że nie ma stricte metod weryfikacji jakościowej tych tekstów, a raczej można założyć, że ich jakość jest niska. Problemem jest też to, iż tak jak w przypadku ChatGPT 3,0 są publicznie dostępne informacje na jakich korpusach językowych jest on oparty, to w przypadku wersji 4,0 nie ma takiej informacji. Tak więc, tak naprawdę nie znamy jego konstrukcji. Dlaczego jest to ważne? Ponieważ konstrukcja korpusów językowych bezpośrednio wpływa na jakość informacji. Zgodnie z logiką, jeżeli do określonego systemu dostarczymy śmieci „na wejściu", to też z niego otrzymamy śmieci na „wyjściu".
Warto zwrócić uwagę na prosty eksperyment. Profesor Surma poprosił Chata GPT o odpowiedzenie na poniższe pytanie (prompta) 1 – patrz grafika poniżej:
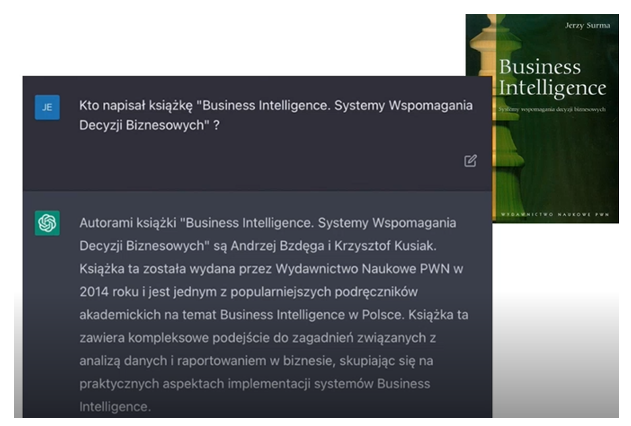
Autorem książki „Business Intelligence. Systemy Wspomagania Decyzji Biznesowych" jest Jerzy Surma i tylko Jerzy Surma. A więc ChatGPT w tym momencie sobie wymyślił dwóch autorów. W dodatku są to postacie fikcyjne. Czat nie tylko stworzył te postacie, ale również wygenerował dla nich pozycje literatury, które prezentuje poniższy zrzut ekranu:

Te pozycje nie istnieją, ale warto zwrócić uwagę, że ich zapis jest poprawny i tym samym wyglądają one wiarygodnie. Niestety sprawdzenie wiarygodności treści generowanych przez sztuczną inteligencję jest niezwykle czaso- i pracochłonne. Dokładne przedstawienie powyższego autorskiego śledztwa Jerzego Surmy można znaleźć na kanale profesora na You Tubie2.
Kolejnym problemem modeli LLM jest cenzura. Przed wprowadzeniem do publicznej przestrzeni takie rozwiązania jak ChatGPT były szeroko testowane przez ludzi pod kątem tego, na jakie pytania mogą lub nie mogą odpowiadać (poprzez technikę reinforcement learning with human feednack). Przykładowo, ChatGPT nie powinien szerzyć rasistowskich czy faszystowskich treści. Kłopotem jest jednak to, że proces cenzury nie jest transparentny. Jak wynika z badań Jerzego Surmy, niektóre treści są blokowane, a niektóre nie (np. ChatGPT potrafi opowiedzieć dowcip o Polakach, a nie opowie dowcipu o innych narodowościach).
Główne konkluzje z prezentacji to:
- LLM są stronnicze, co wynika wprost z doboru korpusów językowych do zbiorów treningowych.
- Treści generowane przez LLM mogą być cenzurowane w kontekście polityk bezpieczeństwa twórców modelu.
- LLM mogą generować halucynacje i nie są znane obecnie metody identyfikacji tych „zachowań”.
- LLM mogą generować niską jakość treści a nawet krytyczne błędy (np. kody programistyczne generowane przez AI mają przeważnie błędy bezpieczeństwa).
- Nie są znane obecnie metody wiarygodnej identyfikacji treści generowanych przez AI.
Czy zatem w ogóle AI jest użyteczne? Oczywiście, że tak. Po pierwsze, główne problemy z generowanymi treściami przez LLM wynikają z tego, że „na wejściu” są śmieci i tym samym „na wyjściu” również są śmieci. Stąd też skorzystanie z oprogramowania, które umożliwia np. analizę artykułów, które sami wgramy do niego może się okazać bardzo przydatne i owocne i nie powinno skutkować słabymi jakościowo rezultatami. Przykładowo oprogramowanie do analizy jakościowej danych MAXQDA uruchomiła już (albo już prawie uruchomiła) analizę wprowadzonych przez autora danych w oparciu o AI. Analizy artykułów umożliwia również baza Scopus.
Po drugie, AI świetnie się sprawdza jako korekta językowa tekstów. Potrafi tworzyć poprawne struktury semantyczne i tym samym jesteśmy w stanie w miarę szybko i również tanio przetłumaczyć teksty, np. na język angielski. Najprostsza procedura tutaj to najpierw przetłumaczenie tekstu przez Google Translator, a potem właśnie przepuszczenie go przez oprogramowanie AI do korekty językowej – dzięki temu możemy napisać tekst w stylu biznesowym, formalnym czy akademickim w wersji brytyjskiej, amerykańskiej czy australijskiej angielskiego.
W tym duchu toczą się obecnie prace w Szkole Głównej Handlowej w Warszawie nad zasadami wykorzystania sztucznej inteligencji przy przygotowywaniu prac pisemnych. Zasady te będą obowiązywały na studiach licencjackich, magisterskich, podyplomowych, a także będą dotyczyć rozpraw doktorskich. Pracami kieruje profesor Tymoteusz Doligalski; dokument już powstał, był przedmiotem konsultacji m.in. z radami programowymi kierunków. Aktualnie dokument przechodzi przez ścieżkę legislacyjną (stan na 31 stycznia 2024 roku).
Jeszcze raz serdecznie zapraszamy Państwa na kolejne webinaria. Najbliższe będzie miało miejsce 29 lutego 2024 roku. Informacje o nim ukażą się w drugiej połowie lutego.
Dorobek dotychczasowych webinariów dostępny jest w Gazecie SGH-a pod linkiem.
1 To jest prompt w uproszczonej wersji. Dla pełnej treści prompt’a, z uwzględnieniem kontekstu zapytania, w ChatGPT w wersji 3.5 otrzymano podobny rezultat.
2 https://youtu.be/8ou45RwMd6o?feature=shared, dostęp: 2024.02.02


