
Pierniczek Graneruda, czyli pułapki klikbajtu. Sprostowanie do artykułu GW: „Prokuratura prawie skończyła liczyć głosy"

W miniony weekend na portalu Wyborcza.pl ukazał się artykuł „Prokuratura prawie skończyła liczyć głosy. Nieoficjalnie: szacunki biegłych się nie potwierdzają". W tekście pojawiło się sporo nieścisłości i poważnych zniekształceń interpretacyjnych, wynikających z pobieżnego zaznajomienia się z treścią ekspertyzy. Publikujemy sprostowanie przygotowane przez prof. Andrzeja Torója.
Dr hab. ANDRZEJ TORÓJ, prof. SGH,
wicedyrektor Instytutu Ekonometrii, Kolegium Analiz Ekonomicznych SGH
Żyjemy w erze klikbajtu i wszyscy staramy się mieć świadomość jej trudów zarówno dla czytelników, jak i dziennikarzy. Kilka lat temu w sieci pojawił się nagłówek ze świata skoków narciarskich: „Piękny gest Graneruda, oddał ukraińskiemu skoczkowi nagrodę”. Po kliknięciu i wykazaniu pewnej cierpliwości przy przewijaniu czytelnik mógł się dowiedzieć, że Halvor Egner Granerud otrzymał za zwycięstwo w zawodach Pucharu Świata puchar, pieniądze i pierniczek, po czym oddał koledze właśnie ten pierniczek. Można to potraktować jako anegdotę, ale trudno pogodzić się z podobnym stylem informowania o sprawach o szczególnej wadze dla państwa.
Celem niniejszego tekstu jest sprostowanie podobnych niedopowiedzeń w głośnej sprawie tzw. anomalii statystycznych w II turze tegorocznych wyborów prezydenckich. Analizy ekonometryczne są – jak wiadomo – materią techniczną, trudną w komunikacji, a więc łatwo tu o zniekształcenia. Wiele z tych zniekształceń dotyczy treści opinii, którą przygotowałem w charakterze biegłego powołanego przez Prokuraturę Krajową.
W ubiegły piątek w serwisie Wyborcza.pl pojawił się nagłówek: „Prokuratura prawie skończyła liczyć głosy”. Nieoficjalnie: szacunki socjologów się nie potwierdzają”. Socjologami nazwano w tym wypadku umownie biegłych, którzy przygotowywali opinie w sprawie tzw. anomalii statystycznych w wynikach powtórnego głosowania w tegorocznych wyborach prezydenckich. Umownie, bo gwoli ścisłości: jestem ekonomistą i ekonometrykiem, a nie socjologiem. Nie noszę też imienia Adam i wbrew treści poprzedniego artykułu „Gazety Wyborczej” na ten temat (z 30.06.2025 r.) posiadam stopień doktora habilitowanego. Z kolei autor drugiej opinii jest rzeczywiście socjologiem, również po habilitacji, w tekście z 30.06.2025 r. niesłusznie powiązanym ze Szkołą Główną Handlową w Warszawie. To jednak szczegóły bez większego znaczenia dla wagi sprawy.
Wersja internetowa artykułu nie jest powszechnie dostępna, warto więc może napisać, co dokładnie się nie potwierdziło, gdy chodzi o szacunki. Otóż – jak wyjaśniają informatorzy „Gazety Wyborczej” z Prokuratury Krajowej – nie potwierdziło się, że rewizja wyniku powtórnego głosowania w wyborach prezydenckich osiągnie skalę 18 tysięcy na korzyść kandydata przegranego. Liczba 18 tys. rzeczywiście jest przywołana w opinii, którą sporządziłem.em. Rozpatruję tam trzy scenariusze, czyli zestawy założeń, przy których szacowana jest skala możliwej rewizji wyniku. Obok dwóch scenariuszy realistycznych, rozważony został też scenariusz skrajny: mało prawdopodobny, ale jego rozpatrzenie jest istotne z perspektywy odpowiedzi na pytanie, czy anomalie mogły, choćby z minimalnym prawdopodobieństwem, zaważyć na wyniku wyborów… przy założeniach skrajnie korzystnych dla kandydata, który otrzymał niższą liczbę głosów. Z tym właśnie „skrajnym” scenariuszem wiąże się liczba 18 tys. Określenia kursywą pochodzą wprost z opinii, z którą każdy może się zapoznać na stronach Prokuratury Krajowej. W rzeczy samej skrajne i mało prawdopodobne scenariusze zazwyczaj się nie potwierdzają.
Artykuł z wydania „Gazety Wyborczej”, które pojawiło się w kioskach 21 lipca br., a w internecie było dostępne w ubiegły piątek, przywołuje słowa informatora z Prokuratury Krajowej: „To jest mikroskala. (…) Spodziewaliśmy się tysięcy przypadków, a jest ich dużo mniej”. W podstawowym scenariuszu z przywołanej wcześniej opinii biegłego, przy bardziej zachowawczych i realistycznych założeniach, podawana jest liczba 266 (dwieście sześćdziesiąt sześć głosów; sztuk, a nie tysięcy sztuk). Ta liczba to efekt netto, w którym uwzględnia się możliwe pomyłki w obie strony. Gdy porównamy to z różnicą głosów w II turze (ponad 369 tys.), da się tu z pewnością użyć określenia „mikroskala”, nie da się jednak powiedzieć, że przewidywanie się nie potwierdza.
W artykule znalazła się jeszcze jedna, na swój sposób istotna nieścisłość. Pada tam stwierdzenie, jakoby biegli „podważali metodę” innego spośród badaczy opisywanego zjawiska. Nie może to być prawdą w moim wypadku, bo ani w opinii dla Prokuratury Krajowej, ani w żaden inny sposób nie komentowałem wyników uzyskiwanych przez innych badaczy, zostawiając porównania i wnioski Czytelnikom. Sam fakt, że szerokie grono badaczy sięga do wyników głosowania jako materiału analitycznego, należy ocenić pozytywnie jako pewien element kontroli społecznej nad procesem wyborczym.
Z powyższych powodów, ale także z szacunku dla instytucji Prokuratury Krajowej uznałem, że uczestnictwo w polemikach publicystycznych wykracza poza rolę biegłego. W rezultacie, choć ja sam nie odnoszę się do analiz innych, to inni – co zrozumiałe – odnoszą się do mojej. Nie oznacza to jednak, że nie śledzę dyskusji i nie jestem gotów objaśniać wyników własnej analizy szerszej publiczności. Docierają do mnie, rzecz jasna, głosy krytyczne podające w wątpliwość zasadność wykorzystania regresji liniowej jako narzędzia w analizie. Nie lekceważę ich i zgadzam się co do zasady, że nie należy stosować tej metody bezrefleksyjnie, chociażby w ramach proponowanych aktualnie rozwiązań algorytmicznego sprawdzania wyników spływających z Okręgowych Komisji Wyborczych (OKW) i automatycznego typowania komisji do ewentualnego ponownego przeliczenia. Nieodmiennie uważam jednak, że w przypadku tegorocznych wyborów to narzędzie jest właściwe.
Pisząc „to narzędzie”, nieco upraszczam: podstawowe wnioski z mojej analizy zostały sformułowane przy użyciu modelu błędów przestrzennie skorelowanych (SEM), którego założenia różnią się od modelu regresji liniowej. Nieprawdą jest, że w modelu SEM abstrahuje się od specyfiki najbliższej okolicy danej OKW, którą to opinię niezbyt krytycznie cytuje „Gazeta Wyborcza” w artykule z 30 czerwca 2025 r. Nie ma to jednak większego znaczenia, jeśli wziąć pod uwagę główne argumenty krytyków: dotyczą one tak modelu regresji liniowej, jak i modelu przestrzennego SEM oraz, patrząc szerzej, każdej innej metody tzw. uczenia nadzorowanego (nie wykluczając tu niekiedy metod faworyzowanych przez samych krytyków).
Na czym polegają te argumenty? Model dopasowany do danych potencjalnie zafałszowanych będzie przewidywał inaczej niż model, który hipotetycznie można byłoby dopasować do danych niezafałszowanych, gdybyśmy tylko nimi dysponowali. Rozważmy to, dla uproszczenia wywodu, na przykładzie regresji liniowej z jednym predyktorem. W mojej analizie znalazły się dwa podobne modele objaśniające zmianę poparcia każdego z kandydatów w poszczególnych OKW między I a II turą kilkunastoma zmiennymi (uproszczenie nie wpływa na treść zasadniczego argumentu). Jeżeli prawdziwe poparcie dla kandydata w poszczególnych OKW (zielone punkty) jest systematycznie zaniżane przy zliczaniu (czerwone punkty), to wartości przewidywane przez model (czerwona linia prosta) będą wyznaczone błędnie. Tym samym, jak twierdzą przeciwnicy metod uczenia nadzorowanego, zmieni się odczyt różnic między wartościami zaobserwowanymi a wyznaczonymi przez model, zmniejszając liczbę i wagę sygnałów alarmowych.
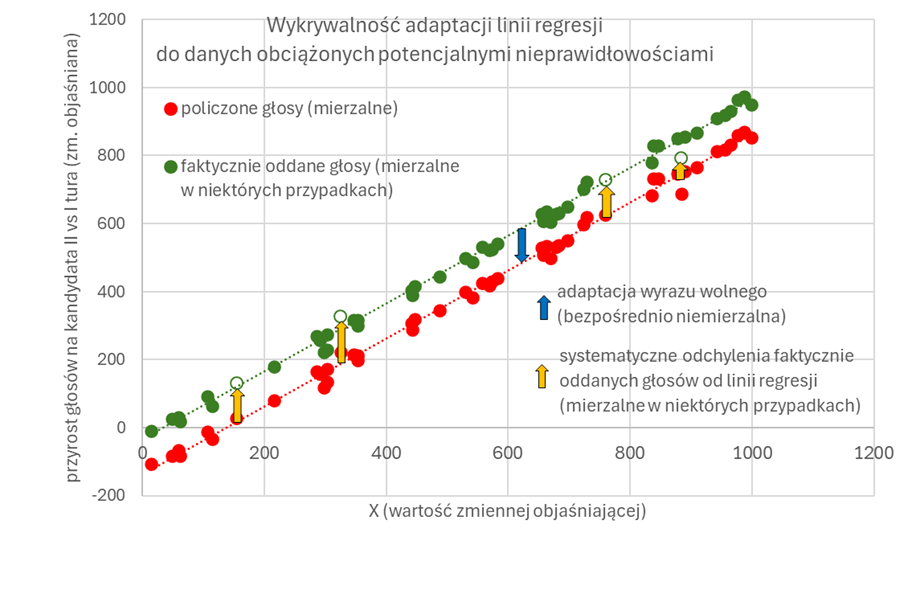
Dlaczego w przypadku tegorocznych wyborów nie uznałem tych argumentów za zasadne? Z czterech zasadniczych powodów.
Po pierwsze, zniekształcenie wyniku o drobną wartość w bardzo dużej liczbie OKW wymagałoby masowych, skoordynowanych, kosztownych organizacyjnie działań. Ocena ich prawdopodobieństwa wykracza poza ramy analizy statystycznej czy ekonometrycznej, jednak moi rozmówcy pracujący w różnych OKW (obojgu dziękuję!) i znający „kuchnię” procesu zgodnie uznali taki schemat za dalece mniej prawdopodobny niż ewentualne zniekształcenia na większą skalę w ograniczonej liczbie komisji. To oczywiście argument pozastatystyczny, którego ocenę pozostawiam osobom bezpośrednio zaangażowanym w proces wyborczy.
Po drugie, jak łatwo zauważyć na wykresie, w przypadku dużej liczby drobnych fałszerstw na korzyść jednego z kandydatów adaptacja linii regresji do ewentualnie zafałszowanych danych odbywa się poprzez równoległe przesunięcie (granatowa strzałka), czyli – w naszym żargonie – zmianę wyrazu wolnego, który w tym modelu powinien być bliski zera. Jeżeli schemat nieprawidłowości polegałby na błędnym przypisywaniu głosów obu kandydatom na masową skalę (a analiza obiegu kart i głosów nieważnych raczej wykluczają inne możliwości), to jedna z linii regresji powinna przesunąć się w górę, co oznaczałoby dodatni wyraz wolny, a druga w dół (ujemny). Tymczasem ocena wyraz wolny w obu modelach jest stosunkowo bliska zeru (choć różni się istotnie, o co przy liczbie obserwacji powyżej 31 tys. nietrudno) i co ważniejsze ma dodatni znak i porównywalną wartość bezwzględną. Oceny parametrów przy zmiennych objaśniających też posiadają intuicyjną interpretację, którą ułatwiają dość jednoznaczne przepływy elektoratów między turami tegorocznych wyborów.
Po trzecie, w momencie sporządzania opinii znane były wyniki powtórnego przeliczenia głosów w kilkunastu wybranych OKW. Uznajmy, że na wykresie obrazują je wybrane zielone punkty (te z białym wypełnieniem). Ich systematyczne, jednostronne odchylenia od czerwonej linii regresji (oznaczone pomarańczowymi strzałkami) powinny zostać uznane za sygnał alarmowy. Tymczasem model SEM objaśniający zmianę poparcia dla przegranego kandydata lokuje 15 takich punktów niemal dokładnie na czerwonej linii, przewidując w 5 przypadkach wartość nieco wyższą, w 7 nieco niższą, a w 2 trafiając w punkt. Średnia różnica między przewidywaniem modelu a wartościami ponownie przeliczonymi w tych przypadkach to mniej niż 4 głosy. Podobny jest obraz dla kandydata wygranego. Można oczywiście argumentować, że 15 OKW to niewielka próbka. Wyniki ponownego przeliczania głosów pod nadzorem Prokuratury Krajowej w 296 OKW – być może znane już Czytelnikom niniejszego tekstu w momencie lektury, choć nieznane mi jeszcze w momencie pisania tego tekstu – nie będą już obarczone tym zastrzeżeniem.
Po czwarte, na podstawie modelu SEM sporządziłem ranking wszystkich OKW pod kątem prawdopodobieństwa i skali nieprawidłowości. 9 komisji, w których (na moment sporządzania opinii) potwierdzono pomyłkę na niekorzyść kandydata przegranego, zajęło w tym rankingu miejsca: 1, 2, 4, 6, 7, 8, 9, 10, 15 i 17 (w tym ostatnim przypadku: częściową pomyłkę). OKW, w których podejrzenia nie potwierdziły się, zajęły w tym rankingu miejsca 1376 oraz 20972. Innymi słowy, komisje, w których doszło do potwierdzonych nieprawidłowości, zapełniają ścisłą czołówkę rankingu, a nie np. miejsca 100, 200 i 300, co pozwalałoby sądzić, że między nimi byłyby ulokowane setki lub choćby dziesiątki komisji, w których także doszło do pomyłek.
Powyższe argumenty to element sporów merytorycznych, które zawsze będą się toczyć. Rozstrzygający będzie oficjalny raport Prokuratury Krajowej z ponownego przeliczenia głosów w wybranych komisjach, które – jak słusznie zauważają dziennikarze „Gazety Wyborczej” – są przez poszczególnych badaczy typowane dość zgodnie.
Mam nadzieję, że niniejszy tekst i zawarte w nim objaśnienia pozwolą wszystkim zainteresowanym na świadomą lekturę tego raportu, stanowiąc zachętę do sięgnięcia do tekstów źródłowych, które nie są obarczone medialnymi zniekształceniami. Polecam do tej lektury jakąś dobrą przekąskę, na przykład pierniczek.


